Datatek, Inc.
1735 Guess Road, Suite 200
Durham, NC 27701
Email: info@datatek-net.com
Sales: sales@datatek-net.com
Web: webmaster@datatek-net.com
USA & CANADA: 800-536-4835
International: 919-416-9771
Language Conversion Tour :: Process
| Conversion Tour | Overview | Process | Advantages | Resources | Contact Us |
|---|
Datatek’s Language Conversion Process
In Brief
Our language conversion process is an iterative process. In general, the code, including copybooks/include/macro files, is parsed (similar to that of a compiler) and put into a metadata format. This information is then correlated with other modules, making the necessary modifications for handling the differences between the source and target programming languages. Information needed for other modules is then split out to feed into those source code conversions, creating a “cross pollination” effect which ensures that the information needed by a module is carried through the entire conversion process code base. The final code is then generated.
Process Diagram
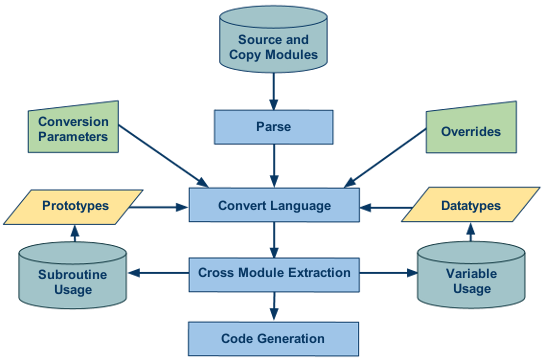
Successive passes through the entire code set gather additional information during each stage. This provides the ability to perform complex code manipulations and conversions resulting in better and more maintainable converted code.
The Conversion Process in More Detail
As can be seen in the diagram above, the process begins with the parsing of a source file and its copy/include/macro modules into a metadata format. The parsed information is fed into the language converter along with additional information that may be pertinent to the conversion, including data types, prototypes, conversion parameters, and overrides:
Data Types
Data type information is extremely useful especially in cases where the target programming language may not support a data type that was available in the original source language. In cases where the target is an object-orientated language, certain base classes will usually be required that did not exist in the original code.
Prototypes
Prototype information allows parameter information to be available for target languages that require it. For example, a target language might require/enforce a called routine’s parameters to exactly match those of the routine and the target language may or may not support implicit parameter conversion that may have been available in the source language.
Conversion Parameters
Conversion parameters provide information to the converter for the definition of rules pertinent to particular conversion scenarios. For example, a client may request a specific conversion option which is specific to their environment and in only a particular circumstance.
Overrides
Functionality overrides provide the ability to bypass or modify functional behavior. For instance, file pathnames may need to be modified due to incompatibilities between operating system functionality access.
Once all of these components have been passed to the converter, information that is required for other modules is extracted, such as variable, parameter, and subroutine usage. From this, a determination is made about how variables are used. For example, a routine that passes a variable must be examined to determine whether the variable is to be passed by value or reference.
The conversion process then becomes iterative. With each successive pass through the entire code set, additional information is generated, since a change to one module can create the domino effect of requiring modifications in other modules. Changes to those modules, can then require modifications to another set of modules, and so on. By having the ability to quickly and repetitively parse through entire code sets, making additional modifications on-the-fly, it is clear that Datatek’s automated language conversions are the most cost effective and reliable way to convert between programming languages.

Language Conversion Tour

Source Languages We Convert
Strategic Partners
